







Récemment, le professeur associé à la voie tenure-track de l'École d'Ingénieurs Paris SJTU, Guillaume Salha Galvan, a présenté des résultats importants à la 42e Conférence internationale sur l'apprentissage machine (ICML 2025), une conférence internationale de premier plan en intelligence artificielle. Son article de recherche co-écrit, intitulé « Exploring Large Action Sets with Hyperspherical Embeddings using von Mises-Fisher Sampling », a été sélectionné avec succès pour cette édition de la conférence et officieusement publié ce mois-ci à Vancouver, au Canada.
Cette recherche se concentre sur le problème des espaces d'action à grande échelle dans l'apprentissage par renforcement, proposant la méthode vMF-exp, une stratégie d'exploration efficace basée sur des représentations vectorielles d'embeddings hypersphériques. Lorsqu'elle traite des espaces d'action à grande échelle, cette méthode performe mieux que l'échantillonnage Boltzmann traditionnel en termes d'efficacité d'exploration et d'extensibilité. Les résultats ont été appliqués avec succès à Deezer, une plateforme de streaming musical líder mondial, améliorant de manière significative l'expérience de découverte musicale personnalisée de millions d'utilisateurs, démontrant ainsi la valeur d'application de la recherche académique dans l'industrie.
Le professeur associé Guillaume Salha Galvan est coauteur correspondant de l'article. Cette recherche a été menée en collaboration avec plusieurs partenaires français, notamment le Dr Walid Bendada (premier auteur) et le professeur Tristan Cazenave du laboratoire LAMSADE de l'Université Paris Dauphine (PSL), ainsi que le Dr Romain Hennequin, le Dr Thomas Bouabça et Théo Bontempelli de Deezer, une entreprise de streaming musical.


Contexte de la recherche
Le mécanisme d'« exploration » est un composant clé de l'apprentissage par renforcement, permettant aux agents de percevoir activement l'environnement et d'identifier les chemins d'action optimaux. Cependant, à mesure que le nombre d'actions possibles croît de manière exponentielle, le processus d'exploration est confronté à une complexité et à des charges computationnelles croissantes.
Prenons exemple sur les plateformes de streaming musical telles que Spotify, Deezer ou Tencent Music : elles recommandent généralement des playlists aux utilisateurs via des vecteurs d'embeddings de chansons pré-calculés. Bien qu'efficaces, ces méthodes sont par nature statiques et peinent à s'ajuster dynamiquement en fonction des comportements en temps réel des utilisateurs (par exemple, likes, skips). Si les tâches de recommandation sont modélisées comme des problèmes d'apprentissage par renforcement, les systèmes peuvent atteindre une optimisation continue basée sur les retours utilisateurs. Cependant, cela pose un défi : les agents doivent prendre des décisions en temps réel parmi des millions de chansons candidates, augmentant considérablement la difficulté d'exploration et les coûts computationnels.
Les stratégies d'exploration traditionnelles comme l'« exploration Boltzmann » sont coûteuses en termes de calcul à cette échelle et difficiles à mettre en œuvre ; les stratégies aléatoires, bien qu'elles soient dans une certaine mesure extensibles, conduisent souvent à des recommandations hors sujet, nuisant à l'expérience utilisateur. Les systèmes industriels du monde réel utilisent principalement des mécanismes de traitement par lots hors ligne, et les contraintes de ressources limitent davantage le déploiement de stratégies déterministes ou naïves. Ainsi, l'industrie utilise généralement des méthodes approximatives telles que l'échantillonnage par troncature du pool de candidats. Cependant, améliorer la qualité d'exploration dans les espaces d'action à grande échelle tout en garantissant l'efficacité reste un défi clé — et cette recherche propose une solution innovante pour relever ce goulot d'étranglement critique.
Résultats innovants
Cette étude présente vMF-exp, une méthode d'exploration efficace pour les ensembles d'action à grande échelle dans l'apprentissage par renforcement, particulièrement adaptée aux scénarios de tâches où les actions sont représentées par des vecteurs d'embeddings hypersphériques. La méthode échantillonne des directions sur la sphère hypersphérique unitaire en se basant sur la distribution von Mises-Fisher (vMF) et explore les actions adjacentes à ces directions. Elle bénéficie d'une excellente efficacité computationnelle et d'une grande extensibilité, supportant la sélection rapide parmi des millions d'actions candidates.
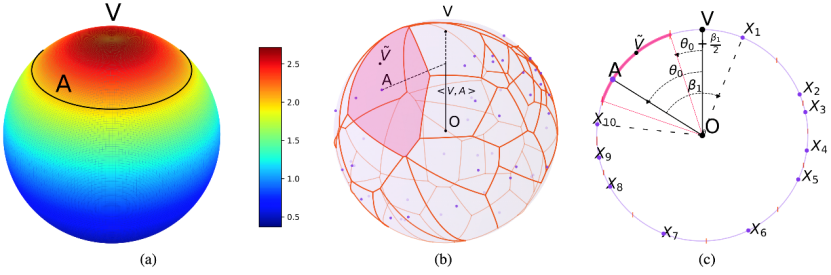
Figure 1:
L'article propose une analyse mathématique systématique de la méthode vMF-exp, prouvant qu'elle possède plusieurs propriétés souhaitables dans les tâches d'exploration à grande échelle. Plus précisément, vMF-exp ne se limite pas à des voisinages fixes, mais échantillonne en fonction de la similarité des embeddings, améliorant la qualité d'exploration tout en garantissant l'extensibilité et l'efficacité. Dans le cadre d'analyse théorique, le comportement d'exploration asymptotique de vMF-exp s'aligne sur les stratégies Boltzmann, tout en surmontant les goulots d'étranglement computationnels de ces dernières dans des environnements à grande échelle, devenant ainsi une alternative plus pratiquement réalisable.
La recherche fournit non seulement un soutien théorique, mais vérifie également l'efficacité de la méthode par des validations empiriques. vMF-exp s'est révélée performante sur plusieurs ensembles de données synthétiques et des ensembles de données publiques issues de scénarios d'application réels, et a été déployée à grande échelle sur la plateforme de streaming musical mondial Deezer. Sur cette plateforme, vMF-exp fonctionne de manière stable depuis plusieurs mois, offrant des recommandations de « playlists inspirées » personnalisées à millions d'utilisateurs, avec une exploration couvrant des millions de chansons (Figure 2). Le système a été validé par des tests A/B en ligne pour vérifier son utilisabilité et son efficacité de recommandation dans un environnement réel, démontrant suffisament la valeur d'application de vMF-exp dans des tâches de découverte musicale à grande échelle et adaptative.
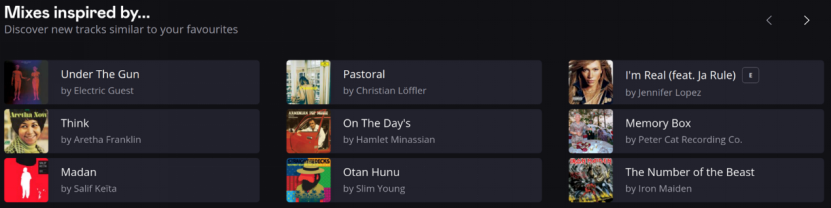
Figure 2 : Interface du système de recommandation « Mixes Inspired By » de la plateforme Deezer. Le système présente des recommandations personnalisées en fonction des chansons préférées de l'utilisateur ; cliquer sur une chanson génère une playlist de « sources d'inspiration ». La méthode vMF-exp fonctionne de manière stable depuis plusieurs mois dans l'environnement de production de ce système, utilisée pour générer des contenus recommandés et soutenir l'exploration intelligente d'une bibliothèque de millions de chansons.
Présentation de l'auteur

Guillaume Salha Galvan est professeur associé à la voie tenure-track à l'École d'Ingénieurs Paris SJTU. Il a travaillé précédemment comme scientifique de recherche à Deezer, une plateforme de streaming musical française, accumulant une riche expérience dans les applications d'intelligence artificielle et la transformation industrielle. Il a obtenu un doctorat en informatique à l'École Polytechnique (IP Paris) et, précédemment, un double master en mathématiques, vision par ordinateur et apprentissage machine à l'École Normale Supérieure de Paris-Saclay et à l'École Nationale de la Statistique et de l'Administration Économique (ENSAE Paris). Ses recherches portent depuis longtemps sur l'apprentissage profond, l'exploration de données graphiques et les systèmes de recommandation musicales. Ses résultats ont été largement appliqués aux systèmes de recommandation à grande échelle de Deezer, améliorant de manière significative l'expérience de découverte musicale de millions d'utilisateurs. À ce jour, il a publié près de 30 articles de haut niveau couvrant plusieurs fronts de l'intelligence artificielle et de la science des données.
Liens vers le texte intégral
arXiv: https://arxiv.org/pdf/2507.00518
ICML: https://icml.cc/virtual/2025/poster/45873