







Recently, Associate Professor Guillaume Salha Galvan, Tenure-Track Faculty at SJTU Paris Elite Institute of Technology (SPEIT), presented significant findings at the 42nd International Conference on Machine Learning (ICML 2025), a top-tier international conference in artificial intelligence. His co-authored research paper, "Exploring Large Action Sets with Hyperspherical Embeddings using von Mises-Fisher Sampling," was successfully selected for this year’s conference and officially released in Vancouver, Canada, this month.
The research focuses on the problem of large-scale action spaces in reinforcement learning, proposing the vMF-exp method—an efficient exploration strategy based on hyperspherical embedding vector representations. When handling large-scale action spaces, this method outperforms traditional Boltzmann sampling in terms of exploration efficiency and scalability. The result has been successfully applied to Deezer, a world-leading music streaming platform, significantly enhancing the personalized music discovery experience for millions of users, fully demonstrating the application value of academic research in industry.
Associate Professor Guillaume Salha Galvan is a co-corresponding author of the paper. This research was completed in collaboration with multiple French partners, including Dr. Walid Bendada (first author) and Professor Tristan Cazenave from the LAMSADE Laboratory at Université Paris Dauphine (PSL), as well as Dr. Romain Hennequin, Dr. Thomas Bouabça, and Théo Bontempelli from Deezer, a music streaming company.


Research Background
The "exploration" mechanism is a core component of reinforcement learning, enabling agents to actively perceive the environment and identify optimal action paths. However, as the number of optional actions grows exponentially, the exploration process faces increasing complexity and computational burdens.
Take music streaming platforms such as Spotify, Deezer, or Tencent Music as examples: they typically recommend playlists to users through precomputed song embedding vectors. While efficient, such methods are inherently static and struggle to dynamically adjust based on real-time user behaviors (e.g., likes, skips). If recommendation tasks are modeled as reinforcement learning problems, systems can achieve continuous optimization based on user feedback. However, this brings a challenge: agents must make real-time decisions from millions of candidate songs, significantly increasing exploration difficulty and computational costs.
Traditional exploration strategies like "Boltzmann exploration" are computationally expensive at this scale and difficult to implement; random strategies, though somewhat scalable, often lead to irrelevant recommendations, harming user experience. Real-world industrial systems mostly use offline batch processing mechanisms, and resource constraints further limit the deployment of deterministic or naive strategies. Thus, the industry commonly uses approximate methods such as candidate pool truncation sampling. However, improving exploration quality in large-scale action spaces while ensuring efficiency remains a key challenge—and this research proposes an innovative solution to address this critical bottleneck.
Innovative Achievements
This study presents vMF-exp, an efficient exploration method for large-scale action sets in reinforcement learning, particularly suitable for task scenarios where actions are represented by hyperspherical embedding vectors. The method samples directions on the unit hypersphere based on the von Mises-Fisher (vMF) distribution and explores actions adjacent to these directions. It boasts excellent computational efficiency and scalability, supporting rapid selection among millions of candidate actions.
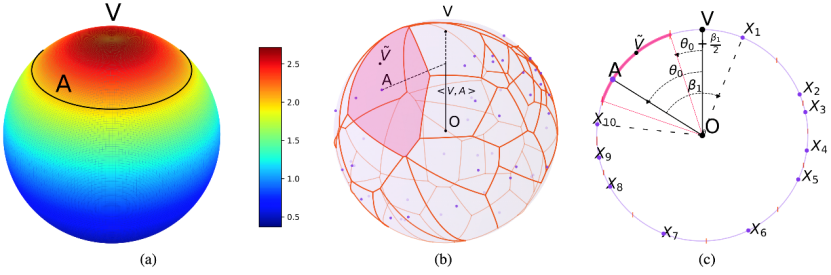
Figure 1: The paper provides a systematic mathematical analysis of the vMF-exp method, proving that it possesses multiple desirable properties in large-scale exploration tasks. Specifically, vMF-exp is not limited to fixed neighborhoods but flexibly samples based on embedding similarity, improving exploration quality while ensuring scalability and efficiency. Within the theoretical analysis framework, the asymptotic exploration behavior of vMF-exp aligns with Boltzmann strategies, while overcoming the latter’s computational bottlenecks in large-scale environments, making it a more practically feasible alternative.
The research not only provides theoretical support but also verifies the method’s effectiveness through empirical validation. vMF-exp performed excellently on multiple synthetic datasets and public datasets from real-world applications, and has been deployed on a large scale on Deezer, a global music streaming platform. On this platform, vMF-exp has operated stably for months, providing personalized "inspired playlist" recommendations to millions of users, with exploration covering millions of songs (Figure 2). The system has passed online A/B testing to verify its usability and recommendation effectiveness in real environments, fully demonstrating vMF-exp’s application value in large-scale, adaptive music discovery tasks.
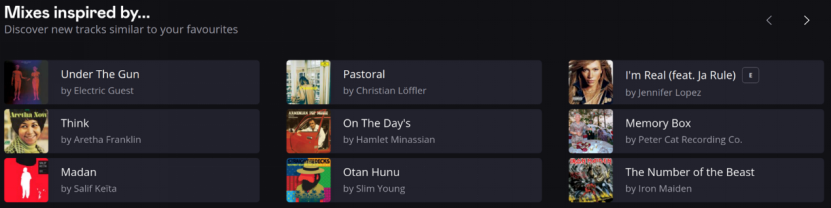
Figure 2: Interface of Deezer’s "Mixes Inspired By" recommendation system. The system presents personalized recommendations based on users’ favorite songs; clicking any song generates a "source of inspiration" playlist. The vMF-exp method has operated stably in the system’s production environment for months, generating recommendations and supporting intelligent exploration of a million-scale music library.
Author Introduction

Guillaume Salha Galvan is a Tenure-Track Associate Professor at SPEIT, Shanghai Jiao Tong University. He previously served as a Research Scientist at Deezer, a French music streaming platform, accumulating rich experience in AI applications and industrial transformation. He holds a Ph.D. in Computer Science from École Polytechnique (IP Paris) and a dual master’s degree in Mathematics, Computer Vision, and Machine Learning from ÉNS Paris-Saclay and ENSAE Paris (École Nationale de la Statistique et de l’Administration Économique). His research long focuses on deep learning, graph data mining, and music recommendation systems. His findings have been widely applied to Deezer’s large-scale recommendation systems, significantly enhancing the music exploration experience for millions of users. To date, he has published nearly 30 high-impact papers covering multiple frontiers in artificial intelligence and data science.
Full Text Links
arXiv: https://arxiv.org/pdf/2507.00518
ICML: https://icml.cc/virtual/2025/poster/45873